Wer ist der optimale Java Bean Mapper?
Ich hatte ein Problem. Ich hatte einen Webservice zu implementieren.
Dabei musste ich die interne Objekthierarchie einer Anwendung auf ca. 23 Servicemethoden mappen. Zusätzlich musste der Webservice aus einem komplexen Objektgeflecht bestückt werden.
Hätte ich dieses Mapping von Hand programmiert, wäre ich Wochen damit beschäftigt gewesen. Eine Lösung dieses Problems sind die Java Bean Mapper.
In diesem Beitrag zeige ich, welche Java Bean Mapper es gibt und welche Probleme damit gelöst bzw. aufgetreten sind.
Zusätzlich habe ich die Performanz der Java Bean Mappers miteinander verglichen.
Die Aufgabe
… ist ein typisches Problem aus der Praxis. Das Mappen von strukturierten Daten an Schnittstellen bzw. in Endpoints.
Dort werden die Daten der Schnittstelle auf die interne Objekthierarchie der Anwendung gemappt.
Dabei können bei einer umfangreichen Schnittstelle mit einem komplexen Sachverhalt recht aufwändige Objektgeflechte entstehen. Erschwerend kommt noch die Verschiedenartigkeit der aneinandergrenzenden Anwendungsschichten (Persistenz-, Domain-, Service-, REST- oder Web-API) hinzu.
Werden diese Objektgeflechte von Hand gemappt, sind Fehler vorprogrammiert. Daher wird immer die Frage nach einem automatischen Mapping gestellt.
Zur Lösung des Problems fiel meine Wahl auf den Klassiker – Dozer.
Leider stellte sich recht schnell heraus, dass die Performanz dieses Mappers nicht ausreichend für die Lösung des Problems war.
Probleme über Probleme
Bei der Suche nach alternativen Java Bean Mapper traten weitere Hindernisse auf.
- Einige Mapper kamen mit den generierten JAXB-Klassen nicht zurecht, da die JAXB-Klassen nicht nach dem Java Bean Standard generiert werden. Die Collections haben keinen Setter Methoden und die Getter Methoden liefern immer eine Collection zurück.
public class XmlTable implements Serializable {
protected List<XmlRow> rows;
public List<XmlRow> getRows() {
if (rows == null) {
rows = new ArrayList<XmlRow>();
}
return this.rows;
}
}
- Auch die erweiterte Generierung der JAXB-Klassen mit dem XJC-Plugin
jaxb2-basicshalf nicht weiter. - Dieses Plugin generiert für die Collections Setter Methoden. Aber bei einem nicht gesetzten Property wird die Setter Methode mit
nullaufgerufen. Daran stört sich aber die MethodeaddAll().
public void setRows(List<XmlRow> value) {
this.rows = null;
List<XmlRow> draftl = this.getRows();
draftl.addAll(value);
}
- Einige Mapper können nicht rekursiv durch die Objekthierarchie iterieren.
- Somit wurden die in Collections enthaltenen Objekte nicht gemappt – sondern nur kopiert. Dadurch landeten nicht die erwarteten Klassen in den gemappten Objekten.
- Ein Beispiel ist das Mappen einer
DomainTableauf eineXmlTable. Beide Klassen haben ein Propertyrows. Im Falle derDomainTableist das Property vom TypList<DomainRow> rows;und derXmlTablevom TypList<XmlRow> rows;. Nach dem Mappen vonDomainTableauf dieXmlTablebefindet sich im Property Objekte vom TypDomainRow.
Die Testimplementation
Wie hab ich den Test aufgebaut?
Der Test besteht aus zwei Testläufen, die die obengenannten Probleme berücksichtigt.
- Die Objekthierarchie wird vollständig mit Daten gefüllt.
Leider können nicht alle Java Bean Mapper bei diesem Test eingeschossen werden. Die Mapper, die die obengenannten Probleme haben, wurden hier nicht berücksichtigt. - Die Objekthierarchie wird teilweise mit Daten gefüllt.
Bei diesem einfachen Test konnten alle Java Bean Mapper berücksichtigt werden. Allerdings ist die Aussagefähigkeit dieses Tests in der Praxis fraglich, da wesentliche Funktionen fehlen.
Die Links zum Quellcode finden Sie weiter unten.
Die Objekthierarchie
In diesem Beispiel werden zwei Objekthierarchien (JAXB– und JPA-Klassen) aufeinander gemappt. Es wird der Standard Jakarta EE 10 verwendet.
Die Eingangsdatenstruktur wurde aus der WSDL (https://xmlns.frank-rahn.de/ws/test/1.0) einmalig per JAXB generiert. Die generierten Klassen wurden danach im Source-Verzeichnis abgelegt.
Die Ausgangsdatenstruktur besteht aus JPA Entities.
In den folgenden UML-Diagrammen sind die Objekthierarchien der JAXB– und JPA-Klassen dargestellt.
")
")
Der JUnit Test
In der Klasse AbstractPerformanceTest wird in der Methode runTestWithMapper() für jeden Java Bean Mapper das Mapping durchgeführt. Für jeden Durchlauf werden die Daten erfasst. Vor jeder Messreihe werden alle Mapper 10-mal aufgerufen, um den Test bzw. die Implementationen einzuschwingen. Der eigentliche Test läuft dann 10 Minuten.
Es wird die durchschnittliche Dauer in Abhängigkeit von der Anzahl der Durchläufe ermittelt.
Zusätzlich werden folgende Kenndaten über die Dauer ermittelt.
- Minimaler Wert
- Maximaler Wert
- Letzter gemessener Wert
- Arithmetischer Mittelwert
- Standardabweichung
Die Ergebnisse werden in einem Excel-Sheet dargestellt. Die Dauer wird in Millisekunden angegeben.
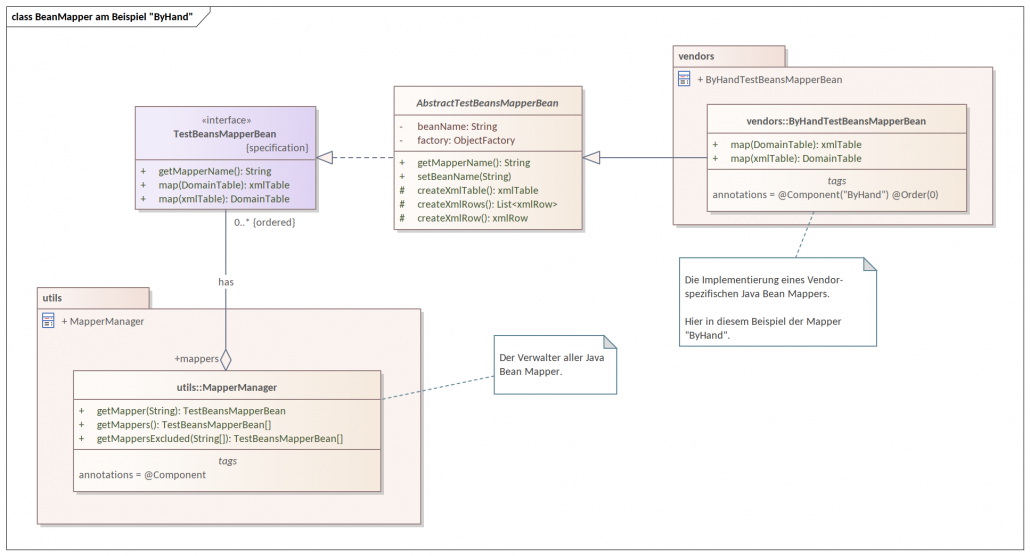
Im folgenden Klassendiagramm ist die Objekthierarchie des JUnit-Tests dargestellt.
Das Klassendiagramm für den Java Bean Mapper Test am Beispiel 'ByHand' (© Frank Rahn)
Die getesteten Java Bean Mapper mit Bewertung und Hinweise zur Implementierung
Bei der Implementierung habe ich darauf geachtet, dass keine Technik zum Einsatz kommt, die eine direkte Änderung des Quellcodes der JAXB- bzw. JPA-Klassen erzwungen hätte. Z. B. durch den Einsatz einer speziellen Annotation eines Mapper Frameworks.
Die folgenden Java Bean Mapper wurden von mir untersucht.
ByHand
Der Java Bean Mapper ByHand ist kein automatisch generierter Mapper.
Dieser Java Bean Mapper ist eine Implementierung von Hand (hand coded). Hierbei wird jedes einzelne Property von einem Java Bean in ein anderes Java Bean, ggf. mit Typkonvertierung, übertragen.
Das Erstellen dieses Mappers ist sehr zeitintensiv und fehleranfällig. Eigentlich eine Aufgabe für einen dressierten Affen. Allerdings können alle fachlichen Aspekte individuell berücksichtigt werden.
Diese Art von Mappern liefert die beste Performanz.
/**
* Der Mapper per "ByHand".
*
* @author Frank W. Rahn
*/
@Component("ByHand")
@Order(0)
public class ByHandTestBeansMapperBean extends AbstractTestBeansMapperBean {
/**
* {@inheritDoc}
*
* @see TestBeansMapperBean#map(DomainTable)
*/
@Override
public XmlTable map(DomainTable source) throws Exception {
return map(createXmlTable(), source);
}
/**
* {@inheritDoc}
*
* @see TestBeansMapperBean#map(XmlTable)
*/
@Override
public DomainTable map(XmlTable source) throws Exception {
return map(new DomainTable(), source);
}
private DomainRow map(DomainRow target, XmlRow source) {
// Mapping String
target.setColumn00(source.getColumn00());
target.setColumn01(source.getColumn01());
target.setColumn02(source.getColumn02());
target.setColumn03(source.getColumn03());
target.setColumn04(source.getColumn04());
target.setColumn05(source.getColumn05());
target.setColumn06(source.getColumn06());
target.setColumn07(source.getColumn07());
target.setColumn08(source.getColumn08());
target.setColumn09(source.getColumn09());
// Mapping int
target.setColumn10(source.getColumn10());
target.setColumn11(source.getColumn11());
target.setColumn12(source.getColumn12());
target.setColumn13(source.getColumn13());
target.setColumn14(source.getColumn14());
target.setColumn15(source.getColumn15());
target.setColumn16(source.getColumn16());
target.setColumn17(source.getColumn17());
target.setColumn18(source.getColumn18());
target.setColumn19(source.getColumn19());
// Mapping boolean
target.setColumn20(source.isColumn20());
target.setColumn21(source.isColumn21());
target.setColumn22(source.getColumn22());
target.setColumn23(source.isColumn23());
target.setColumn24(source.isColumn24());
target.setColumn25(source.isColumn25());
target.setColumn26(source.isColumn26());
target.setColumn27(source.isColumn27());
target.setColumn28(source.isColumn28());
target.setColumn29(source.isColumn29());
// Mapping long
target.setColumn30(source.getColumn30());
target.setColumn31(source.getColumn31());
target.setColumn32(source.getColumn32());
target.setColumn33(source.getColumn33());
target.setColumn34(source.getColumn34());
target.setColumn35(source.getColumn35());
target.setColumn36(source.getColumn36());
target.setColumn37(source.getColumn37());
target.setColumn38(source.getColumn38());
target.setColumn39(source.getColumn39());
// Mapping BigDecimal
target.setColumn40(source.getColumn40());
target.setColumn41(source.getColumn41());
target.setColumn42(source.getColumn42());
target.setColumn43(source.getColumn43());
target.setColumn44(source.getColumn44());
target.setColumn45(source.getColumn45());
target.setColumn46(source.getColumn46());
target.setColumn47(source.getColumn47());
target.setColumn48(source.getColumn48());
target.setColumn49(source.getColumn49());
// Mapping Calendar
target.setColumn50(source.getColumn50());
target.setColumn51(source.getColumn51());
target.setColumn52(source.getColumn52());
target.setColumn53(source.getColumn53());
target.setColumn54(source.getColumn54());
target.setColumn55(source.getColumn55());
target.setColumn56(source.getColumn56());
target.setColumn57(source.getColumn57());
target.setColumn58(source.getColumn58());
target.setColumn59(source.getColumn59());
// Mapping String
target.setColumn60(source.getColumn60());
target.setColumn61(source.getColumn61());
target.setColumn62(source.getColumn62());
target.setColumn63(source.getColumn63());
target.setColumn64(source.getColumn64());
target.setColumn65(source.getColumn65());
target.setColumn66(source.getColumn66());
target.setColumn67(source.getColumn67());
target.setColumn68(source.getColumn68());
target.setColumn69(source.getColumn69());
// Mapping int
target.setColumn70(source.getColumn70());
target.setColumn71(source.getColumn71());
target.setColumn72(source.getColumn72());
target.setColumn73(source.getColumn73());
target.setColumn74(source.getColumn74());
target.setColumn75(source.getColumn75());
target.setColumn76(source.getColumn76());
target.setColumn77(source.getColumn77());
target.setColumn78(source.getColumn78());
target.setColumn79(source.getColumn79());
// Mapping String[]
if (source.getColumns() != null) {
target.setColumns(new ArrayList<>(source.getColumns()));
}
return target;
}
private DomainTable map(DomainTable target, XmlTable source) {
target.setName(source.getName());
if (source.getDate() != null) {
target.setDate(source.getDate().getTime());
}
if (source.getRows().isEmpty()) {
target.setRows(new ArrayList<DomainRow>());
} else {
List<DomainRow> rows = new ArrayList<>();
for (XmlRow xmlRow : source.getRows()) {
rows.add(map(new DomainRow(), xmlRow));
}
target.setRows(rows);
}
return target;
}
private XmlRow map(XmlRow target, DomainRow source) {
// Mapping String
target.setColumn00(source.getColumn00());
target.setColumn01(source.getColumn01());
target.setColumn02(source.getColumn02());
target.setColumn03(source.getColumn03());
target.setColumn04(source.getColumn04());
target.setColumn05(source.getColumn05());
target.setColumn06(source.getColumn06());
target.setColumn07(source.getColumn07());
target.setColumn08(source.getColumn08());
target.setColumn09(source.getColumn09());
// Mapping int
target.setColumn10(source.getColumn10());
target.setColumn11(source.getColumn11());
target.setColumn12(source.getColumn12());
target.setColumn13(source.getColumn13());
target.setColumn14(source.getColumn14());
target.setColumn15(source.getColumn15());
target.setColumn16(source.getColumn16());
target.setColumn17(source.getColumn17());
target.setColumn18(source.getColumn18());
target.setColumn19(source.getColumn19());
// Mapping boolean
target.setColumn20(source.isColumn20());
target.setColumn21(source.isColumn21());
target.setColumn22(source.getColumn22());
target.setColumn23(source.isColumn23());
target.setColumn24(source.isColumn24());
target.setColumn25(source.isColumn25());
target.setColumn26(source.isColumn26());
target.setColumn27(source.isColumn27());
target.setColumn28(source.isColumn28());
target.setColumn29(source.isColumn29());
// Mapping long
target.setColumn30(source.getColumn30());
target.setColumn31(source.getColumn31());
target.setColumn32(source.getColumn32());
target.setColumn33(source.getColumn33());
target.setColumn34(source.getColumn34());
target.setColumn35(source.getColumn35());
target.setColumn36(source.getColumn36());
target.setColumn37(source.getColumn37());
target.setColumn38(source.getColumn38());
target.setColumn39(source.getColumn39());
// Mapping BigDecimal
target.setColumn40(source.getColumn40());
target.setColumn41(source.getColumn41());
target.setColumn42(source.getColumn42());
target.setColumn43(source.getColumn43());
target.setColumn44(source.getColumn44());
target.setColumn45(source.getColumn45());
target.setColumn46(source.getColumn46());
target.setColumn47(source.getColumn47());
target.setColumn48(source.getColumn48());
target.setColumn49(source.getColumn49());
// Mapping Calendar
target.setColumn50(source.getColumn50());
target.setColumn51(source.getColumn51());
target.setColumn52(source.getColumn52());
target.setColumn53(source.getColumn53());
target.setColumn54(source.getColumn54());
target.setColumn55(source.getColumn55());
target.setColumn56(source.getColumn56());
target.setColumn57(source.getColumn57());
target.setColumn58(source.getColumn58());
target.setColumn59(source.getColumn59());
// Mapping String
target.setColumn60(source.getColumn60());
target.setColumn61(source.getColumn61());
target.setColumn62(source.getColumn62());
target.setColumn63(source.getColumn63());
target.setColumn64(source.getColumn64());
target.setColumn65(source.getColumn65());
target.setColumn66(source.getColumn66());
target.setColumn67(source.getColumn67());
target.setColumn68(source.getColumn68());
target.setColumn69(source.getColumn69());
// Mapping int
target.setColumn70(source.getColumn70());
target.setColumn71(source.getColumn71());
target.setColumn72(source.getColumn72());
target.setColumn73(source.getColumn73());
target.setColumn74(source.getColumn74());
target.setColumn75(source.getColumn75());
target.setColumn76(source.getColumn76());
target.setColumn77(source.getColumn77());
target.setColumn78(source.getColumn78());
target.setColumn79(source.getColumn79());
// Mapping String[]
if (source.getColumns() == null) {
target.setColumns(null);
} else {
target.setColumns(new ArrayList<>(source.getColumns()));
}
return target;
}
private XmlTable map(XmlTable target, DomainTable source) {
target.setName(source.getName());
if (source.getDate() != null) {
Calendar calendar = Calendar.getInstance();
calendar.setTime(source.getDate());
target.setDate(calendar);
}
if (source.getRows() != null) {
for (DomainRow domainRow : source.getRows()) {
target.getRows().add(map(createXmlRow(), domainRow));
}
}
return target;
}
}
Apache Commons BeanUtils
Dieser Java Bean Mapper ist Teil der Bibliothek Apache Commons BeanUtils der Apache Software Foundation. Dieses Projekt stellt nützliche Tools rund um den Standard JavaBeans Component API java.beans.Introspector zu Verfügung und verwendet zum Mappen Reflection (reflection-based).
Der Mapper besteht aus der Klasse org.apache.commons.beanutils.BeanUtils. Dieser Mapper kann das zumappende Objekt nicht rekursive bearbeiten und ist auf die Setter Methode angewiesen – ohne diese kann er die Werte nicht mappen.
Daher kann er nur für einfache und nicht tiefgreifende Mappings verwendet werden.
In diesen Fällen allerdings liefert er eine gute Performanz und ist sehr einfach eingesetzt.
/**
* Der Mapper für {@link BeanUtils}.
*
* @author Frank W. Rahn
*/
@Component("Commons-BeanUtils")
@Order(1)
public class CommonsBeanUtilsTestBeansMapperBean extends AbstractTestBeansMapperBean {
/**
* {@inheritDoc}
*
* @see TestBeansMapperBean#map(DomainTable)
*/
@Override
public XmlTable map(DomainTable source) throws Exception {
XmlTable target = createXmlTable();
BeanUtils.copyProperties(target, source);
return target;
}
/**
* {@inheritDoc}
*
* @see TestBeansMapperBean#map(XmlTable)
*/
@Override
public DomainTable map(XmlTable source) throws Exception {
DomainTable target = new DomainTable();
BeanUtils.copyProperties(target, source);
return target;
}
}
Spring Framework BeanUtils
Dieser Java Bean Mapper ist Teil vom Spring Framework und wird intern vom Spring Framework selber verwendet.
Der Mapper besteht aus der Klasse org.springframework.beans.BeanUtils. Diese Klasse nutzt den Standard JavaBeans Component API java.beans.Introspector und verwendet Reflection (reflection-based).
Dieser Mapper arbeitet ähnlich wie die Apache Common BeanUtils, hat die gleichen Probleme und liefert die gleiche Performanz.
Update (01.01.2020): Seit der Spring Framework Version 5.3 hat sich das Vorgehen beim Mappen von Collection geändert. Die generischen Typinformationen werden jetzt berücksichtigt. Dadurch werden Collection nur noch gemappt, wenn der generische Typ passt. Vorher war die Klasse der Collection entscheidend.
/**
* Der Mapper für {@link BeanUtils}.
*
* @author Frank W. Rahn
*/
@Component("Spring-BeanUtils")
@Order(2)
public class SpringBeanUtilsTestBeansMapperBean extends AbstractTestBeansMapperBean {
/**
* {@inheritDoc}
*
* @see TestBeansMapperBean#map(DomainTable)
*/
@Override
public XmlTable map(DomainTable source) throws Exception {
XmlTable target = createXmlTable();
BeanUtils.copyProperties(source, target);
return target;
}
/**
* {@inheritDoc}
*
* @see TestBeansMapperBean#map(XmlTable)
*/
@Override
public DomainTable map(XmlTable source) throws Exception {
DomainTable target = new DomainTable();
BeanUtils.copyProperties(source, target);
return target;
}
}
Dozer
Der Java Bean Mapper Dozer ist ein komplettes Mapping Framework.
Dozer verwendet den Standard JavaBeans Component API java.beans.Introspector und Reflection (reflection-based) zum Erzeugen der Mapper und kann die Objekte rekursiv durcharbeiten.
Dozer kann über eine XML-Datei umfangreich konfiguriert werden. Die Möglichkeiten der Konfiguration dieses Mappers lassen keine Wünsche offen.
Wie beim Mapper ByHand können alle individuellen fachlichen Aspekte berücksichtigt werden. Die Konfiguration geht schnell vonstatten.
Leider liefert dieser Mapper aber auch die schlechteste Performanz.
/**
* Der Mapper für {@link Mapper}.
*
* @author Frank W. Rahn
*/
@Component("Dozer")
@Order(3)
public class DozerTestBeansMapperBean extends AbstractTestBeansMapperBean {
private Mapper dozer;
/**
* Initialisiere diese Spring-Bean.
*/
@PostConstruct
public void initialize() {
dozer = DozerBeanMapperBuilder.create()
// Bekannt geben, dass die Xml*-Klassen JAXB Objekte sind
.withMappingBuilder(new BeanMappingBuilder() {
@Override
protected void configure() {
mapping(new TypeDefinition(DomainTable.class),
new TypeDefinition(XmlTable.class).beanFactory(JAXBBeanFactory.class));
}
})
.withMappingBuilder(new BeanMappingBuilder() {
@Override
protected void configure() {
mapping(new TypeDefinition(DomainRow.class),
new TypeDefinition(XmlRow.class).beanFactory(JAXBBeanFactory.class));
}
})
.build();
}
@Override
public XmlTable map(DomainTable source) throws Exception {
return dozer.map(source, XmlTable.class);
}
@Override
public DomainTable map(XmlTable source) throws Exception {
return dozer.map(source, DomainTable.class);
}
}
Update (Fehlende Versionen 6.0.0 bis 6.5.0): Hier ist mir leider ein Fehler unterlaufen. Wenn ich in diesen Beitrag aktualisieren, schaue ich immer in den zentralen Maven-Repositories nach, ob dort neue Versionen veröffentlicht wurden. Dabei verwende ich die Maven-Suche mit dem Artefaktnamen. In diesem Punkt habe ich leider die Änderung im Artefaktnamen (net.sf.dozer:dozer → com.github.dozermapper:dozer-core) übersehen und so hat sich nie die Versionsnummer geändert.
Update (07.04.2021): Dieser Mapper wird nicht mehr weiterentwickelt.
The project is currently not active and will more than likely be deprecated in the future.
https://github.com/DozerMapper/dozer/blob/master/README.md#project-activity
Update (05.03.2024): Es ist eine neue Version 7.0.0 aufgetaucht, ob wohl der Mapper nicht mehr weiter entwickelt wird. Eine Aktivierung des Projektes ist aber nicht geschehen.
Orika
Der Java Bean Mapper Orika ist ähnlich wie Dozer ein Mapping Framework.
Im Grunde stellt Orika einen Replacment von Dozer mit gleichem Funktionsumfang dar.
Allerdings verwendet Orika die Bytecode Generierung von Javassist zum Erzeugen der Mapper. Dadurch hat Orika, bei gleichem Funktionsumfang, eine deutlich bessere Performanz als Dozer. Allerdings können die generierten Mapper nicht debuggt werden.
/**
* Der Mapper für {@link MapperFacade}.
*
* @author Frank W. Rahn
*/
@Component("Orika")
@Order(4)
public class OrikaTestBeansMapperBean extends AbstractTestBeansMapperBean {
private MapperFacade orika;
/**
* Initialisiere diese Spring-Bean.
*/
@PostConstruct
public void initialize() {
MapperFactory factory = new DefaultMapperFactory.Builder().build();
orika = factory.getMapperFacade();
}
/**
* {@inheritDoc}
*
* @see TestBeansMapperBean#map(DomainTable)
*/
@Override
public XmlTable map(DomainTable source) throws Exception {
return orika.map(source, XmlTable.class);
}
/**
* {@inheritDoc}
*
* @see TestBeansMapperBean#map(XmlTable)
*/
@Override
public DomainTable map(XmlTable source) throws Exception {
return orika.map(source, DomainTable.class);
}
}
Update (22.09.2023): Wie in den Kommentaren beschrieben, ist dieser Mapper nicht unter Java 17 lauffähig. Daher werde ich diesen Mapper nicht mehr berücksichtigen.
Fehler:java.lang.reflect.InaccessibleObjectException: Unable to make protected native java.lang.Object java.lang.Object.clone() throws java.lang.CloneNotSupportedException accessible: module java.base does not "opens java.lang" to unnamed module
Befehlszeile mit JVM-Optionen:$ java --add-opens=java.base/java.lang=ALL-UNNAMED -jar app.jar
Update (02.01.2026): Ich habe das Maven-Plugin maven-surefire-plugin, um die oben genannten JVM-Optionen erweitert. Damit konnte der Mapper unter Java 21 wieder berücksichtigt werden.
MapStruct
Der Java Bean Mapper MapStruct ist auch ein Mapping Framework.
Allerdings geht dieser Mapper einen kompletten neuen Weg.
Er verwendet einen Annotation Processor (APT) zum Erzeugen von Mappern für die einzelnen Java Beans. Diese generierten Mapper sind richtige Java-Klassen – können also im Fehlerfall auch debuggt werden.
Als Ausgangsbasis dient dem Prozessor ein Interface oder eine abstrakte Basisklasse.
Falls Sie sich für eine abstrakte Basisklasse entscheiden, kann diese Klasse eine individuelle Implementierungen liefern. Damit erreicht dieses Mapping den vollständigen Funktionsumfang wie der Mapper ByHand. Allerdings auch zu einem höheren Implementierungsaufwand im Gegensatz zu Dozer oder Orika.
Diese Interfaces müssen geschrieben werden. Bei einer umfangreichen Objekthierarchie benötigt das Schreiben der Interfaces seine Zeit.
Die dadurch gewonnene Performanz hebt diesen Nachteil allerdings vollständig auf. Dieser Mapper wurde nur geringfügig (im Bereich von Millisekunden) durch den Mapper ByHand geschlagen. Der wesentlich mühseliger zu programmieren ist.
/**
* Der Mapper für MapStruct.
*
* @author Frank W. Rahn
*/
@Component("MapStruct")
@Order(5)
public class MapStructTestBeansMapperBean extends AbstractTestBeansMapperBean {
@Autowired
private TestBeansMapper testBeansMapper;
/**
* {@inheritDoc}
*
* @see TestBeansMapperBean#map(DomainTable)
*/
@Override
public XmlTable map(DomainTable source) throws Exception {
return testBeansMapper.domainTableToXmlTable(source);
}
/**
* {@inheritDoc}
*
* @see TestBeansMapperBean#map(XmlTable)
*/
@Override
public DomainTable map(XmlTable source) throws Exception {
return testBeansMapper.xmlTableToDomainTable(source);
}
}
ModelMapper
Die Berücksichtigung des Java Bean Mapper ModelMapper wurde in den Kommentaren gewünscht.
Dieser Mapper ähnelt in der Funktionsweise den schon vorher beschriebenen Mappern Orika und Dozer. Dieser Mapper verwendet die Bytecode Generierung von cglib. Das Debuggen der erzeugten Mapper gestaltet sich dadurch schwierig.
Dieser Mapper bietet eine API für spezifische Anwendungsfälle an.
/**
* Der Mapper für {@link ModelMapper}.
*
* @author Frank W. Rahn
*/
@Component("ModelMapper")
@Order(6)
public class ModelMapperTestBeansMapperBean extends AbstractTestBeansMapperBean {
private ModelMapper modelMapper;
/**
* Initialisiere diese Spring-Bean.
*/
@PostConstruct
public void initialize() {
modelMapper = new ModelMapper();
}
/**
* {@inheritDoc}
*
* @see TestBeansMapperBean#map(DomainTable)
*/
@Override
public XmlTable map(DomainTable source) throws Exception {
return modelMapper.map(source, XmlTable.class);
}
/**
* {@inheritDoc}
*
* @see TestBeansMapperBean#map(XmlTable)
*/
@Override
public DomainTable map(XmlTable source) throws Exception {
return modelMapper.map(source, DomainTable.class);
}
}
JMapper Framework
Die Berücksichtigung des Java Bean Mapper JMapper Framework wurde in den Kommentaren gewünscht.
Dieser Mapper ähnelt einwenig dem Mapper MapStruct. Auch bei diesem Mapper muss zwingend eine Konfiguration erstellt werden. Beim JMapper kann zwischen drei Konfigurationsvarianten gewählt werden.
- Der Verwendung von Annotationen an den Klassen
- Eine Konfiguration basierend auf einer XML Datei
- Der JMapper API, welche eine programmatische Konfiguration ermöglicht
Ich habe mich in diesem Beispiel für die Variante JMapper API entschieden.
Der JMapper verwendet die Bytecode Generierung von Javassist zum Erzeugen der Mapper. Das Debuggen der erzeugten Mapper gestaltet sich dadurch schwierig.
Die Performanz dieses Mappers ist beeindruckend. Er kann locker mit dem Mapper ByHand mithalten und ist einfacher umzusetzen als der Mapper MapStruct.
Weitere Features dieses Mappers sind …
- Relationales Mapping von mehreren Klassen auf eine Klasse (Many to One) und umgekehrt (One to Many)
- Vererbung von Konfigurationen
/**
* Der Mapper für {@link JMapper}.
*
* @author Frank W. Rahn
*/
@Component("JMapper")
@Order(7)
public class JMapperTestBeansMapperBean extends AbstractTestBeansMapperBean {
private JMapper<XmlTable, DomainTable> domainToXmlMapper;
private JMapper<DomainTable, XmlTable> xmlToDomainMapper;
/**
* Initialisiere diese Spring-Bean.
*/
@PostConstruct
public void initialize() {
JMapperAPI jMapperAPI = new JMapperAPI()
.add(mappedClass(XmlTable.class).add(global())
.add(conversion("dateToCalendar").from("date").to("date")
.body("java.util.Calendar c = java.util.Calendar.getInstance(); c.setTime(${source}); return c;")))
.add(mappedClass(XmlRow.class).add(global()))
.add(mappedClass(DomainTable.class).add(global().excludedAttributes("id"))
.add(conversion("calendarToDate").from("date").to("date").body("return ${source}.getTime();"))
.add(attribute("rows").value("rows").targetClasses(DomainRow.class)))
.add(mappedClass(DomainRow.class).add(global().excludedAttributes("id")));
domainToXmlMapper = new JMapper<>(XmlTable.class, DomainTable.class, jMapperAPI);
xmlToDomainMapper = new JMapper<>(DomainTable.class, XmlTable.class, jMapperAPI);
}
/**
* {@inheritDoc}
*
* @see TestBeansMapperBean#map(DomainTable)
*/
@Override
public XmlTable map(DomainTable source) throws Exception {
return domainToXmlMapper.getDestination(source);
}
/**
* {@inheritDoc}
*
* @see TestBeansMapperBean#map(XmlTable)
*/
@Override
public DomainTable map(XmlTable source) throws Exception {
return xmlToDomainMapper.getDestination(source);
}
}
Update (01.01.2021): Dieser Mapper wird nicht mehr weiterentwickelt. Der Entwickler schrieb im GitHub Issue 88 dazu:
… I’ve lost interest in JMapper …
https://github.com/jmapper-framework/jmapper-core/issues/88
Update (10.12.2022): Wie in den Kommentaren beschrieben, ist dieser Mapper nicht unter Java 17 lauffähig. Daher werde ich diesen Mapper nicht mehr berücksichtigen.
Fehler (XStream):java.lang.reflect.InaccessibleObjectException: Unable to make protected final java.lang.Class java.lang.ClassLoader.defineClass(java.lang.String,byte[],int,int,java.security.ProtectionDomain) throws java.lang.ClassFormatError accessible: module java.base does not "opens java.lang" to unnamed module
java.lang.reflect.InaccessibleObjectException: Unable to make protected final java.lang.Class java.lang.ClassLoader.defineClass(java.lang.String,byte[],int,int,java.security.ProtectionDomain) throws java.lang.ClassFormatError accessible: module java.base does not "opens java.lang" to unnamed module
java.lang.reflect.InaccessibleObjectException: Unable to make field protected java.lang.reflect.InvocationHandler java.lang.reflect.Proxy.h accessible: module java.base does not "opens java.lang.reflect" to unnamed module
java.lang.reflect.InaccessibleObjectException: Unable to make protected java.lang.String java.text.AttributedCharacterIterator$Attribute.getName() accessible: module java.base does not "opens java.text" to unnamed module
java.lang.reflect.InaccessibleObjectException: Unable to make field private static final java.util.Map java.awt.font.TextAttribute.instanceMap accessible: module java.desktop does not "opens java.awt.font" to unnamed module
Befehlszeile mit JVM-Optionen:$ java --add-opens=java.base/java.lang=ALL-UNNAMED --add-opens=java.base/java.util=ALL-UNNAMED --add-opens=java.base/java.lang.reflect=ALL-UNNAMED --add-opens=java.base/java.text=ALL-UNNAMED --add-opens=java.desktop/java.awt.font=ALL-UNNAMED -jar app.jar
Update (02.01.2026): Ich habe das Maven-Plugin maven-surefire-plugin, um die oben genannten JVM-Optionen erweitert. Damit konnte der Mapper unter Java 21 wieder berücksichtigt werden.
Selma
Die Berücksichtigung des Java Bean Mapper Selma wurde in den Kommentaren gewünscht.
Dieser Mapper verwendet einen Annotation Processor (APT) zum Erzeugen der Mapper und ähnelt damit dem schon vorher beschriebenen Mapper MapStruct.
Im Gegensatz zu MapStruct ist der Aufwand für die Implementierung etwas geringer, da nicht für jedes Mapping eine neue Methode definiert werden muss.
/**
* Der Mapper für {@link Selma}.
*
* @author Frank W. Rahn
*/
@Component("Selma")
@Order(8)
public class SelmaTestBeansMapperBean extends AbstractTestBeansMapperBean {
@Autowired
private TestBeansMapper mapper;
/**
* {@inheritDoc}
*
* @see TestBeansMapperBean#map(DomainTable)
*/
@Override
public XmlTable map(DomainTable source) throws Exception {
return mapper.asXmlTable(source);
}
/**
* {@inheritDoc}
*
* @see TestBeansMapperBean#map(XmlTable)
*/
@Override
public DomainTable map(XmlTable source) throws Exception {
return mapper.asDomainTable(source);
}
}
Update (03.01.2021): Seit dem Umstieg auf das OpenJDK v11 (64 Bit, AdoptOpenJDK Hotspot) werden in Eclipse v4.16.0 zwei Fehler angezeigt – trotzdem wird der Mapper generiert. Maven liefert dazu keine Meldungen. Diese Meldungen können ignoriert werden. Dazu gibt es auch eine Meldung in GitHub Issue 204: Migration Java 8 -> Java 11: mapper: java.lang.NullPointerException.
Error while searching builder for field name on InOutType{in=de.rahn.performance.testbeans.DomainTable, out=https.xmlns_frank_rahn_de.types.testtypes._1.XmlTable, outPutAsParam=false} mapper: java.lang.NullPointerException
Error while searching builder for field name on InOutType{in=https.xmlns_frank_rahn_de.types.testtypes._1.XmlTable, out=de.rahn.performance.testbeans.DomainTable, outPutAsParam=false} mapper: java.lang.NullPointerException
Update (04.01.2022): Mittlerweile bin ich von AdoptOpenJDK wieder auf das Standard OpenJDK zurückgewechselt, da dieses sich unter Ubuntu besser ins System (Stichwort: Zertifikate, …) integriert. Wenn ich die Tests in Eclipse ausführe, tritt leider ein Fehler auf. Die Unterobjekte werden nicht mehr gemappt. Ich hab dazu das Erstellen der Messungen verändert. Ab der Version v1.5.3 werden die Excel-Sheets per Maven auf der Kommandozeile erzeugt (Siehe Durchführung der Messungen). Da gibt es den Fehler, wie in Eclipse, nicht.
reMap
Die Berücksichtigung des Java Bean Mapper reMap wurde in den Kommentaren gewünscht.
reMap verwendet die Bytecode Generierung von cglib zur Erzeugung von Mappern. Das Debuggen der erzeugten Mapper gestaltet sich dadurch schwierig.
Der Schwerpunkt von reMap liegt in der Robustheit und einem minimalen Verwaltungsaufwand für Tests.
Durch das Hauptaugenmerk auf Robustheit müssen mehr Angaben zum Mapping gemacht werden, als bei anderen Mappern nötig ist. Aber es ist gewollt, dass hier wenige Automatik greift und einiges dem Compiler überlassen wird.
/**
* Der Mapper für {@link Mapper}.
*
* @author Tom Hombergs
*/
@Component("reMap")
@Order(9)
public class ReMapTestBeansMapperBean implements TestBeansMapperBean {
protected Mapper<DomainTable, XmlTable> domainToXmlTableMapper;
protected Mapper<XmlTable, DomainTable> xmlToDomainTableMapper;
/**
* {@inheritDoc}
*
* @see TestBeansMapperBean#getMapperName()
*/
@Override
public String getMapperName() {
return "reMap";
}
/**
* Initialisiere diese Spring-Bean.
*/
@PostConstruct
public ReMapTestBeansMapperBean initialize() {
Mapper<DomainRow, XmlRow> domainToXmlRowMapper = Mapping.from(DomainRow.class).to(XmlRow.class).mapper();
Mapper<XmlRow, DomainRow> xmlToDomainRowMapper = Mapping.from(XmlRow.class).to(DomainRow.class).mapper();
// @formatter:off
domainToXmlTableMapper = Mapping
.from(DomainTable.class)
.to(XmlTable.class)
.replace(DomainTable::getDate, XmlTable::getDate)
.with(dateToCalendar())
.useMapper(domainToXmlRowMapper)
.mapper();
xmlToDomainTableMapper = Mapping
.from(XmlTable.class)
.to(DomainTable.class)
.replace(XmlTable::getDate, DomainTable::getDate)
.with(calendarToDate())
.useMapper(xmlToDomainRowMapper).mapper();
// @formatter:on
return this;
}
/**
* {@inheritDoc}
*
* @see TestBeansMapperBean#map(DomainTable)
*/
@Override
public XmlTable map(DomainTable source) throws Exception {
return domainToXmlTableMapper.map(source);
}
/**
* {@inheritDoc}
*
* @see TestBeansMapperBean#map(XmlTable)
*/
@Override
public DomainTable map(XmlTable source) throws Exception {
return xmlToDomainTableMapper.map(source);
}
/**
* @return ein Transformer von {@link Date} nach {@link Calendar}
*/
protected Function<Date, Calendar> dateToCalendar() {
return source -> {
if (source == null) {
return null;
}
Calendar c = Calendar.getInstance();
c.setTime(source);
return c;
};
}
/**
* @return ein Transformer von {@link Calendar} nach {@link Date}
*/
protected Function<Calendar, Date> calendarToDate() {
return source -> {
if (source == null) {
return null;
}
return source.getTime();
};
}
}
Im folgenden Quellcode die Beispiele für die Tests des Mappers.
/**
* Test des Mappers für reMap.
*
* @author Tom Hombergs
*/
public class ReMapTestBeansMapperBeanTest extends AbstractTestBeansMapperBeanTest {
/**
* @throws java.lang.Exception
*/
@Before
public void setUp() throws Exception {
mapperBean = new ReMapTestBeansMapperBean().initialize();
}
/**
* Teste den Mapper.
*/
@Test
public void testDomainToXmlTableMapper() throws Exception {
ReMapTestBeansMapperBean reMapTestBeansMapperBean = (ReMapTestBeansMapperBean) mapperBean;
// @formatter:off
AssertMapping.of(reMapTestBeansMapperBean.domainToXmlTableMapper)
.expectReplace(DomainTable::getDate, XmlTable::getDate)
.andTest(reMapTestBeansMapperBean.dateToCalendar())
.ensure();
// @formatter:on
}
/**
* Teste den Mapper.
*/
@Test
public void testXmlToDomainTableMapper() throws Exception {
ReMapTestBeansMapperBean reMapTestBeansMapperBean = (ReMapTestBeansMapperBean) mapperBean;
// @formatter:off
AssertMapping.of(reMapTestBeansMapperBean.xmlToDomainTableMapper)
.expectReplace(XmlTable::getDate, DomainTable::getDate)
.andTest(reMapTestBeansMapperBean.calendarToDate())
.ensure();
// @formatter:on
}
}
Update (21.07.2025): Wie in den Kommentaren beschrieben, ist dieser Mapper nicht unter Java 21 lauffähig. Daher werde ich diesen Mapper nicht mehr berücksichtigen.
Fehler:java.lang.UnsupportedOperationException: Cannot define class using reflection: Unable to make protected java.lang.Package java.lang.ClassLoader.getPackage(java.lang.String) accessible: module java.base does not "opens java.lang" to unnamed module
Befehlszeile mit JVM-Optionen:$ java --add-opens=java.base/java.lang=ALL-UNNAMED -jar app.jar
Update (02.01.2026): Ich habe das Maven-Plugin maven-surefire-plugin, um die oben genannten JVM-Optionen erweitert. Damit konnte der Mapper unter Java 21 wieder berücksichtigt werden.
Das Fazit
In der folgenden Tabelle sind die Durchschnittswerte für ein Mapping mit vollständig gefüllter Objekthierarchie in Millisekunden angegeben. Die Veränderungen zur vorherigen Messung sind Fett markiert.
Die nicht mehr weiterentwickelten Mapper werden so lange weiter getestet, wie sie funktionieren.
Der Link „Anmerkungen“ zeigt auf zusätzlichen Informationen, wie z. B. Inaktivität oder wichtige Änderungen.
Aktualisierung der Messung: neue Versionen von Mapper vom 16.02.2026 (v1.7.2, jdk21-03)
| Arithmetischer Mittelwert | Standardabweichung | |
|---|---|---|
| ByHand (v1.0) | 0,0143 | 0,119 |
| JMapper Framework v1.6.1.CR2 vom 14.12.2016 Anmerkungen | 0,0071 | 0,084 |
| MapStruct v1.6.3 vom 09.11.2024 | 0,0179 | 0,133 |
| Orika v1.5.4 vom 20.02.2019 Anmerkungen | 0,4166 | 0,494 |
| Selma v1.0 vom 01.05.2017 Anmerkungen | 0,4078 | 0,492 |
| reMap v4.4.2 vom 30.07.2025 Anmerkungen | 2,6213 | 0,541 |
| Dozer v7.0.0 vom 05.03.2024 Anmerkungen | 5,2929 | 0,516 |
| ModelMapper v3.2.6 vom 11.11.2025 | 6,5255 | 0,614 |
Unter den folgenden Rahmenbedingungen wurde dieser Test durchgeführt.
- Java Version 21 (64 Bit, OpenJDK)
- Linux Ubuntu 64 Bit 24.04.4 LTS
- Desktop-Rechner
- Speicher 64 GB
- Prozessor AMD® Ryzen 9 3950x 16-core processor × 32
- Grafik NVIDIA Corporation TU104 [GeForce RTX 2070 SUPER]
Aktualisierung der Messung: Alle Mapper wieder berücksichtigt vom 02.01.2026 (v1.7.1, jdk21-02)
| Arithmetischer Mittelwert | Standardabweichung | |
|---|---|---|
| ByHand (v1.0) | 0,0110 | 0,104 |
| JMapper Framework v1.6.1.CR2 vom 14.12.2016 Anmerkungen | 0,0070 | 0,083 |
| MapStruct v1.6.3 vom 09.11.2024 | 0,0175 | 0,131 |
| Orika v1.5.4 vom 20.02.2019 Anmerkungen | 0,3892 | 0,488 |
| Selma v1.0 vom 01.05.2017 Anmerkungen | 0,3932 | 0,489 |
| reMap v4.4.0 vom 05.02.2025 Anmerkungen | 2,6524 | 0,533 |
| Dozer v7.0.0 vom 05.03.2024 Anmerkungen | 6,1400 | 0,553 |
| ModelMapper v3.2.4 vom 20.06.2025 | 6,5886 | 0,618 |
Unter den folgenden Rahmenbedingungen wurde dieser Test durchgeführt.
- Java Version 21 (64 Bit, OpenJDK)
- Linux Ubuntu 64 Bit 24.04.3 LTS
- Desktop-Rechner
- Speicher 64 GB
- Prozessor AMD® Ryzen 9 3950x 16-core processor × 32
- Grafik NVIDIA Corporation TU104 [GeForce RTX 2070 SUPER]
Aktualisierung der Messung: Neu: Java 21 vom 21.07.2025 (v1.7.0, jdk21-01)
| Arithmetischer Mittelwert | Standardabweichung | |
|---|---|---|
| ByHand (v1.0) | 0,0110 | 0,104 |
| MapStruct v1.6.3 vom 09.11.2024 | 0,0146 | 0,120 |
| Selma v1.0 vom 01.05.2017 Anmerkungen | 0,38327 | 0,487 |
| Dozer v7.0.0 vom 05.03.2024 Anmerkungen | 5,1393 | 0,493 |
| ModelMapper v3.2.4 vom 20.06.2025 | 6,2049 | 0,501 |
| Nicht mehr getestete Mapper | |
|---|---|
| Orika v1.5.4 vom 20.02.2019 Anmerkungen | Diese Version ist im Moment unter Java 17 nicht lauffähig |
| reMap v4.4.0 vom 05.02.2025 Anmerkungen | Diese Version ist im Moment unter Java 21 nicht lauffähig |
| JMapper Framework v1.6.1.CR2 vom 14.12.2016 Anmerkungen | Dieser Mapper wird nicht mehr weiterentwickelt (EOL) und ist unter Java 17 nicht mehr lauffähig |
Unter den folgenden Rahmenbedingungen wurde dieser Test durchgeführt.
- Java Version 21 (64 Bit, OpenJDK)
- Linux Ubuntu 64 Bit 24.04.3 LTS
- Desktop-Rechner
- Speicher 64 GB
- Prozessor AMD® Ryzen 9 3950x 16-core processor × 32
- Grafik NVIDIA Corporation TU104 [GeForce RTX 2070 SUPER]
Aktualisierung der Messung: neue Versionen von Mapper vom 01.07.2025 (v1.6.2, jdk17-07)
| Arithmetischer Mittelwert | Standardabweichung | |
|---|---|---|
| ByHand (v1.0) | 0,0126 | 0,111 |
| MapStruct v1.6.3 vom 09.11.2024 | 0,0171 | 0,130 |
| Selma v1.0 vom 01.05.2017 Anmerkungen | 0,3912 | 0,488 |
| reMap v4.4.0 vom 05.02.2025 | 3,6038 | 0,544 |
| Dozer v7.0.0 vom 05.03.2024 Anmerkungen | 5,3138 | 0,529 |
| ModelMapper v3.2.4 vom 20.06.2025 | 6,3757 | 0,563 |
| Nicht mehr getestete Mapper | |
|---|---|
| Orika v1.5.4 vom 20.02.2019 | Diese Version ist im Moment unter Java 17 nicht lauffähig |
| JMapper Framework v1.6.1.CR2 vom 14.12.2016 Anmerkungen | Dieser Mapper wird nicht mehr weiterentwickelt (EOL) und ist unter Java 17 nicht mehr lauffähig |
Unter den folgenden Rahmenbedingungen wurde dieser Test durchgeführt.
- Java Version 17 (64 Bit, OpenJDK)
- Linux Ubuntu 64 Bit 24.04.3 LTS
- Desktop-Rechner
- Speicher 64 GB
- Prozessor AMD® Ryzen 9 3950x 16-core processor × 32
- Grafik NVIDIA Corporation TU104 [GeForce RTX 2070 SUPER]
Aktualisierung der Messung: neue Versionen von Mapper vom 17.05.2025 (v1.6.1, jdk17-06)
| Arithmetischer Mittelwert | Standardabweichung | |
|---|---|---|
| ByHand (v1.0) | 0,0147 | 0,120 |
| MapStruct v1.6.3 vom 09.11.2024 | 0,0165 | 0,127 |
| Selma v1.0 vom 01.05.2017 Anmerkungen | 0,3883 | 0,488 |
| reMap v4.4.0 vom 05.02.2025 | 3,4609 | 0,518 |
| Dozer v7.0.0 vom 05.03.2024 Anmerkungen | 5,4582 | 0,525 |
| ModelMapper v3.2.3 vom 02.05.2025 | 6,2913 | 0,477 |
| Nicht mehr getestete Mapper | |
|---|---|
| Orika v1.5.4 vom 20.02.2019 | Diese Version ist im Moment unter Java 17 nicht lauffähig |
| JMapper Framework v1.6.1.CR2 vom 14.12.2016 Anmerkungen | Dieser Mapper wird nicht mehr weiterentwickelt (EOL) und ist unter Java 17 nicht mehr lauffähig |
Unter den folgenden Rahmenbedingungen wurde dieser Test durchgeführt.
- Java Version 17 (64 Bit, OpenJDK)
- Linux Ubuntu 64 Bit 24.04.2 LTS
- Desktop-Rechner
- Speicher 64 GB
- Prozessor AMD® Ryzen 9 3950x 16-core processor × 32
- Grafik NVIDIA Corporation TU104 [GeForce RTX 2070 SUPER]
Aktualisierung der Messung: Neue: Betriebssystem, Maven-Plugins vom 11.05.2025 (v1.6.0, jdk17-05)
| Arithmetischer Mittelwert | Standardabweichung | |
|---|---|---|
| ByHand (v1.0) | 0,0124 | 0,111 |
| MapStruct v1.5.5.Final vom 23.04.2023 | 0,0155 | 0,124 |
| Selma v1.0 vom 01.05.2017 Anmerkungen | 0,3880 | 0,487 |
| reMap v4.3.2 vom 28.04.2023 | 3,5287 | 0,529 |
| Dozer v6.5.2 vom 07.04.2021 Anmerkungen | 5,5211 | 0,544 |
| ModelMapper v3.2.0 vom 16.10.2023 | 6,5092 | 0,540 |
| Nicht mehr getestete Mapper | |
|---|---|
| Orika v1.5.4 vom 20.02.2019 | Diese Version ist im Moment unter Java 17 nicht lauffähig |
| JMapper Framework v1.6.1.CR2 vom 14.12.2016 Anmerkungen | Dieser Mapper wird nicht mehr weiterentwickelt (EOL) und ist unter Java 17 nicht mehr lauffähig |
Unter den folgenden Rahmenbedingungen wurde dieser Test durchgeführt.
- Java Version 17 (64 Bit, OpenJDK)
- Linux Ubuntu 64 Bit 24.04.2 LTS
- Desktop-Rechner
- Speicher 64 GB
- Prozessor AMD® Ryzen 9 3950x 16-core processor × 32
- Grafik NVIDIA Corporation TU104 [GeForce RTX 2070 SUPER]
Aktualisierung der Messung: neue Versionen von Mapper vom 03.03.2024 (v1.5.10, jdk17-04)
| Arithmetischer Mittelwert | Standardabweichung | |
|---|---|---|
| ByHand (v1.0) | 0,0117 | 0,110 |
| MapStruct v1.5.5.Final vom 23.04.2023 | 0,0142 | 0,118 |
| Selma v1.0 vom 01.05.2017 Anmerkungen | 0,3882 | 0,488 |
| reMap v4.3.2 vom 28.04.2023 | 3,5018 | 0,538 |
| Dozer v6.5.2 vom 07.04.2021 Anmerkungen | 5,2680 | 0,463 |
| ModelMapper v3.2.0 vom 16.10.2023 | 6,2234 | 0,486 |
| Nicht mehr getestete Mapper | |
|---|---|
| Orika v1.5.4 vom 20.02.2019 | Diese Version ist im Moment unter Java 17 nicht lauffähig |
| JMapper Framework v1.6.1.CR2 vom 14.12.2016 Anmerkungen | Dieser Mapper wird nicht mehr weiterentwickelt (EOL) und ist unter Java 17 nicht mehr lauffähig |
Unter den folgenden Rahmenbedingungen wurde dieser Test durchgeführt.
- Java Version 17 (64 Bit, OpenJDK)
- Linux Ubuntu 64 Bit 20.04.6 LTS
- Desktop-Rechner
- Speicher 64 GB
- Prozessor AMD® Ryzen 9 3950x 16-core processor × 32
- Grafik NVIDIA Corporation TU104 [GeForce RTX 2070 SUPER]
Aktualisierung der Messung: Entfernen der Generierung der JAXB-Klassen vom 25.02.2024 (v1.5.9, jdk17-03)
| Arithmetischer Mittelwert | Standardabweichung | |
|---|---|---|
| ByHand (v1.0) | 0,0121 | 0,110 |
| MapStruct v1.5.5.Final vom 23.04.2023 | 0,0141 | 0,118 |
| Selma v1.0 vom 01.05.2017 Anmerkungen | 0,3979 | 0,491 |
| reMap v4.3.2 vom 28.04.2023 | 3,4790 | 0,531 |
| Dozer v6.5.2 vom 07.04.2021 Anmerkungen | 5,2429 | 0,462 |
| ModelMapper v3.1.1 vom 08.12.2022 | 5,9364 | 0,391 |
| Nicht mehr getestete Mapper | |
|---|---|
| Orika v1.5.4 vom 20.02.2019 | Diese Version ist im Moment unter Java 17 nicht lauffähig |
| JMapper Framework v1.6.1.CR2 vom 14.12.2016 Anmerkungen | Dieser Mapper wird nicht mehr weiterentwickelt (EOL) und ist unter Java 17 nicht mehr lauffähig |
Unter den folgenden Rahmenbedingungen wurde dieser Test durchgeführt.
- Java Version 17 (64 Bit, OpenJDK)
- Linux Ubuntu 64 Bit 20.04.6 LTS
- Desktop-Rechner
- Speicher 64 GB
- Prozessor AMD® Ryzen 9 3950x 16-core processor × 32
- Grafik NVIDIA Corporation TU104 [GeForce RTX 2070 SUPER]
Aktualisierung der Messung: neue Versionen der Maven-Plugins vom 18.02.2024 (v1.5.8, jdk17-02)
| Arithmetischer Mittelwert | Standardabweichung | |
|---|---|---|
| ByHand (v1.0) | 0,0112 | 0,105 |
| MapStruct v1.5.5.Final vom 23.04.2023 | 0,0136 | 0,116 |
| Selma v1.0 vom 01.05.2017 Anmerkungen | 0,3869 | 0,488 |
| reMap v4.3.2 vom 28.04.2023 | 3,5139 | 0,545 |
| Dozer v6.5.2 vom 07.04.2021 Anmerkungen | 5,3591 | 0,534 |
| ModelMapper v3.1.1 vom 08.12.2022 | 6,0371 | 0,300 |
| Nicht mehr getestete Mapper | |
|---|---|
| Orika v1.5.4 vom 20.02.2019 | Diese Version ist im Moment unter Java 17 nicht lauffähig |
| JMapper Framework v1.6.1.CR2 vom 14.12.2016 Anmerkungen | Dieser Mapper wird nicht mehr weiterentwickelt (EOL) und ist unter Java 17 nicht mehr lauffähig |
Unter den folgenden Rahmenbedingungen wurde dieser Test durchgeführt.
- Java Version 17 (64 Bit, OpenJDK)
- Linux Ubuntu 64 Bit 20.04.6 LTS
- Desktop-Rechner
- Speicher 64 GB
- Prozessor AMD® Ryzen 9 3950x 16-core processor × 32
- Grafik NVIDIA Corporation TU104 [GeForce RTX 2070 SUPER]
Aktualisierung der Messung: neue Versionen von Mapper und Java 17 vom 22.09.2023 (v1.5.7, jdk17-01)
| Arithmetischer Mittelwert | Standardabweichung | |
|---|---|---|
| ByHand (v1.0) | 0,0124 | 0,112 |
| MapStruct v1.5.5.Final vom 23.04.2023 | 0,0153 | 0,123 |
| Selma v1.0 vom 01.05.2017 Anmerkungen | 0,3766 | 0,485 |
| reMap v4.3.2 vom 28.04.2023 | 3,4448 | 0,525 |
| Dozer v6.5.2 vom 07.04.2021 Anmerkungen | 5,1495 | 0,402 |
| ModelMapper v3.1.1 vom 08.12.2022 | 5,9629 | 0,396 |
| Nicht mehr getestete Mapper | |
|---|---|
| Orika v1.5.4 vom 20.02.2019 | Diese Version ist im Moment unter Java 17 nicht lauffähig |
| JMapper Framework v1.6.1.CR2 vom 14.12.2016 Anmerkungen | Dieser Mapper wird nicht mehr weiterentwickelt (EOL) und ist unter Java 17 nicht mehr lauffähig |
Unter den folgenden Rahmenbedingungen wurde dieser Test durchgeführt.
- Java Version 17 (64 Bit, OpenJDK)
- Linux Ubuntu 64 Bit 20.04.6 LTS
- Desktop-Rechner
- Speicher 64 GB
- Prozessor AMD® Ryzen 9 3950x 16-core processor × 32
- Grafik NVIDIA Corporation TU104 [GeForce RTX 2070 SUPER]
Aktualisierung der Messung: neue Versionen von Mapper vom 03.10.2022 (v1.5.6, jdk11-05)
| Arithmetischer Mittelwert | Standardabweichung | |
|---|---|---|
| ByHand (v1.0) | 0,0126 | 0,122 |
| JMapper Framework v1.6.1.CR2 vom 14.12.2016 Anmerkungen | 0,0066 | 0,081 |
| MapStruct v1.5.2.Final vom 18.06.2022 | 0,0156 | 0,128 |
| Orika v1.5.4 vom 20.02.2019 | 0,2491 | 0,438 |
| Selma v1.0 vom 01.05.2017 Anmerkungen | 0,3822 | 0,495 |
| reMap v4.2.6 vom 23.07.2021 | 3,3470 | 0,554 |
| Dozer v6.5.2 vom 07.04.2021 Anmerkungen | 5,6902 | 0,515 |
| ModelMapper v3.1.0 vom 08.03.2022 | 6,3587 | 0,561 |
Unter den folgenden Rahmenbedingungen wurde dieser Test durchgeführt.
- Java Version 11 (64 Bit, OpenJDK)
- Linux Ubuntu 64 Bit 20.04.5 LTS
- Desktop-Rechner
- Speicher 64 GB
- Prozessor AMD® Ryzen 9 3950x 16-core processor × 32
- Grafik NVIDIA Corporation TU104 [GeForce RTX 2070 SUPER]
Aktualisierung der Messung: neue Version Dozer vom 09.01.2022 (v1.5.5, jdk11-04)
| Arithmetischer Mittelwert | Standardabweichung | |
|---|---|---|
| ByHand (v1.0) | 0,0121 | 0,109 |
| JMapper Framework v1.6.1.CR2 vom 14.12.2016 Anmerkungen | 0,0068 | 0,082 |
| MapStruct v1.4.2.Final vom 31.01.2021 | 0,0136 | 0,117 |
| Orika v1.5.4 vom 20.02.2019 | 0,2961 | 0,458 |
| Selma v1.0 vom 01.05.2017 Anmerkungen | 0,3927 | 0,492 |
| reMap v4.2.6 vom 23.07.2021 | 3,0761 | 0,317 |
| Dozer v6.5.2 vom 07.04.2021 Anmerkungen | 5,8407 | 0,427 |
| ModelMapper v3.0.0 vom 05.01.2022 | 6,2694 | 0,512 |
Unter den folgenden Rahmenbedingungen wurde dieser Test durchgeführt.
- Java Version 11 (64 Bit, OpenJDK)
- Linux Ubuntu 64 Bit 20.04.3 LTS
- Desktop-Rechner
- Speicher 64 GB
- Prozessor AMD® Ryzen 9 3950x 16-core processor × 32
- Grafik NVIDIA Corporation TU104 [GeForce RTX 2070 SUPER]
Aktualisierung der Messung: neue Version von Mappern vom 05.01.2022 (v1.5.4, jdk11-03)
| Arithmetischer Mittelwert | Standardabweichung | |
|---|---|---|
| ByHand (v1.0) | 0,0136 | 0,120 |
| JMapper Framework v1.6.1.CR2 vom 14.12.2016 Anmerkungen | 0,0066 | 0,081 |
| MapStruct v1.4.2.Final vom 31.01.2021 | 0,0144 | 0,119 |
| Orika v1.5.4 vom 20.02.2019 | 0,2893 | 0,456 |
| Selma v1.0 vom 01.05.2017 Anmerkungen | 0,3950 | 0,494 |
| reMap v4.2.6 vom 23.07.2021 | 3,1389 | 0,382 |
| Dozer v5.5.1 vom 22.04.2014 Anmerkungen | 4,3325 | 0,495 |
| ModelMapper v3.0.0 vom 05.01.2022 | 6,5945 | 0,563 |
Unter den folgenden Rahmenbedingungen wurde dieser Test durchgeführt.
- Java Version 11 (64 Bit, OpenJDK)
- Linux Ubuntu 64 Bit 20.04.3 LTS
- Desktop-Rechner
- Speicher 64 GB
- Prozessor AMD® Ryzen 9 3950x 16-core processor × 32
- Grafik NVIDIA Corporation TU104 [GeForce RTX 2070 SUPER]
Aktualisierung der Messung: Neu: OpenJDK vom 04.01.2022 (v1.5.3, jdk11-02)
| Arithmetischer Mittelwert | Standardabweichung | |
|---|---|---|
| ByHand (v1.0) | 0,0138 | 0,117 |
| JMapper Framework v1.6.1.CR2 vom 14.12.2016 Anmerkungen | 0,0065 | 0,080 |
| MapStruct v1.4.1.Final vom 11.10.2020 | 0,0151 | 0,123 |
| Orika v1.5.4 vom 20.02.2019 | 0,2622 | 0,441 |
| Selma v1.0 vom 01.05.2017 Anmerkungen | 0,3913 | 0,489 |
| reMap v4.2.5 vom 31.07.2020 | 3,2375 | 0,461 |
| Dozer v5.5.1 vom 22.04.2014 Anmerkungen | 4,2933 | 0,470 |
| ModelMapper v2.3.9 vom 20.11.2020 | 5,8645 | 0,431 |
Unter den folgenden Rahmenbedingungen wurde dieser Test durchgeführt.
- Java Version 11 (64 Bit, OpenJDK)
- Linux Ubuntu 64 Bit 20.04.3 LTS
- Desktop-Rechner
- Speicher 64 GB
- Prozessor AMD® Ryzen 9 3950x 16-core processor × 32
- Grafik NVIDIA Corporation TU104 [GeForce RTX 2070 SUPER]
Aktualisierung der Messung: Neu: Java 11 vom 03.01.2021 (v1.5.2, jdk11-01)
| Arithmetischer Mittelwert | Standardabweichung | |
|---|---|---|
| ByHand (v1.0) | 0,0113 | 0,105 |
| JMapper Framework v1.6.1.CR2 vom 14.12.2016 Anmerkungen | 0,0061 | 0,078 |
| MapStruct v1.4.1.Final vom 11.10.2020 | 0,0130 | 0,113 |
| Orika v1.5.4 vom 20.02.2019 | 0,2572 | 0,442 |
| Selma v1.0 vom 01.05.2017 Anmerkungen | 0,3913 | 0,489 |
| reMap v4.2.5 vom 31.07.2020 | 3,1177 | 0,346 |
| Dozer v5.5.1 vom 22.04.2014 Anmerkungen | 4,1055 | 0,347 |
| ModelMapper v2.3.9 vom 20.11.2020 | 5,6616 | 0,543 |
Unter den folgenden Rahmenbedingungen wurde dieser Test durchgeführt.
- Java Version 11 (64 Bit, AdoptOpenJDK Hotspot)
- Linux Ubuntu 64 Bit 20.04.1 LTS
- Desktop-Rechner
- Speicher 64 GB
- Prozessor AMD® Ryzen 9 3950x 16-core processor × 32
- Grafik NVIDIA Corporation TU104 [GeForce RTX 2070 SUPER]
Aktualisierung der Messung: neue Versionen von Mappern vom 02.01.2021 (v1.5.1, jdk8-11)
| Arithmetischer Mittelwert | Standardabweichung | |
|---|---|---|
| ByHand (v1.0) | 0,0085 | 0,093 |
| JMapper Framework v1.6.1.CR2 vom 14.12.2016 Anmerkungen | 0,0066 | 0,083 |
| MapStruct v1.4.1.Final vom 11.10.2020 | 0,0144 | 0,121 |
| Orika v1.5.4 vom 20.02.2019 | 0,2386 | 0,431 |
| Selma v1.0 vom 01.05.2017 | 0,5118 | 0,505 |
| reMap v4.2.5 vom 31.07.2020 | 3,7105 | 0,584 |
| Dozer v5.5.1 vom 22.04.2014 Anmerkungen | 4,9984 | 0,371 |
| ModelMapper v2.3.9 vom 20.11.2020 | 5,1850 | 0,531 |
Unter den folgenden Rahmenbedingungen wurde dieser Test durchgeführt.
- Java Version 8 (64 Bit, AdoptOpenJDK Hotspot)
- Linux Ubuntu 64 Bit 20.04.1 LTS
- Desktop-Rechner
- Speicher 64 GB
- Prozessor AMD® Ryzen 9 3950x 16-core processor × 32
- Grafik NVIDIA Corporation TU104 [GeForce RTX 2070 SUPER]
Aktualisierung der Messung: Neu: Rechner, Betriebssystem vom 30.12.2020 (v1.5.0, jdk8-10)
| Arithmetischer Mittelwert | Standardabweichung | |
|---|---|---|
| ByHand (v1.0) | 0,0093 | 0,098 |
| JMapper Framework v1.6.1.CR2 vom 14.12.2016 | 0,0072 | 0,085 |
| MapStruct v1.3.1.Final vom 29.09.2020 | 0,0133 | 0,117 |
| Orika v1.5.4 vom 20.02.2019 | 0,2435 | 0,434 |
| Selma v1.0 vom 01.05.2017 | 0,5040 | 0,509 |
| reMap v4.2.5 vom 31.07.2020 | 3,7207 | 0,618 |
| Dozer v5.5.1 vom 22.04.2014 Anmerkungen | 5,0428 | 0,416 |
| ModelMapper v2.3.8 vom 05.06.2020 | 5,1171 | 0,479 |
Unter den folgenden Rahmenbedingungen wurde dieser Test durchgeführt.
- Java Version 8 (64 Bit, AdoptOpenJDK Hotspot)
- Linux Ubuntu 64 Bit 20.04.1 LTS
- Desktop-Rechner
- Speicher 64 GB
- Prozessor AMD® Ryzen 9 3950x 16-core processor × 32
- Grafik NVIDIA Corporation TU104 [GeForce RTX 2070 SUPER]
Aktualisierung der Messung: neue Versionen von Mappern vom 02.08.2020 (v1.4.4, jdk8-09)
| Arithmetischer Mittelwert | Standardabweichung | |
|---|---|---|
| ByHand (v1.0) | 0,026 | 0,158 |
| JMapper Framework v1.6.1.CR2 vom 14.12.2016 | 0,015 | 0,121 |
| MapStruct v1.3.1.Final vom 29.09.2020 | 0,051 | 0,221 |
| Orika v1.5.4 vom 20.02.2019 | 0,502 | 0,507 |
| Selma v1.0 vom 01.05.2017 | 0,637 | 0,508 |
| reMap v4.2.5 vom 31.07.2020 | 7,544 | 0,822 |
| ModelMapper v2.3.8 vom 05.06.2020 | 10,756 | 1,078 |
| Dozer v5.5.1 vom 22.04.2014 Anmerkungen | 12,161 | 1,431 |
Unter den folgenden Rahmenbedingungen wurde dieser Test durchgeführt.
- Java Version 8 (64 Bit, AdoptOpenJDK Hotspot)
- Linux Ubuntu 64 Bit 18.04.4 LTS
- Desktop-Rechner
- Speicher 12 GB
- Prozessor Intel Core i7 CPU 975 @ 3,33 GHz * 8
Aktualisierung der Messung: Neu: Mapper, Betriebsystem, JDK vom 07.06.2020 (v1.4.3, jdk8-08)
| Arithmetischer Mittelwert | Standardabweichung | |
|---|---|---|
| ByHand (v1.0) | 0,021 | 0,150 |
| JMapper Framework v1.6.1.CR2 vom 14.12.2016 | 0,025 | 0,160 |
| MapStruct v1.3.0.Final vom 10.02.2019 | 0,062 | 0,248 |
| Orika v1.5.4 vom 20.02.2019 | 0,529 | 0,534 |
| Selma v1.0 vom 01.05.2017 | 0,792 | 0,459 |
| reMap v4.1.5 vom 06.02.2019 | 2,968 | 0,609 |
| Dozer v5.5.1 vom 22.04.2014 Anmerkungen | 12,026 | 1,282 |
| ModelMapper v2.3.2 vom 26.11.2018 | 36,158 | 2,507 |
Unter den folgenden Rahmenbedingungen wurde dieser Test durchgeführt.
- Java Version 8 (64 Bit, AdoptOpenJDK Hotspot)
- Linux Ubuntu 64 Bit 18.04.4 LTS
- Desktop-Rechner
- Speicher 12 GB
- Prozessor Intel Core i7 CPU 975 @ 3,33 GHz * 8
Aktualisierung der Messung: neue Versionen von Mappern vom 10.12.2018 (v1.4.2, jdk8-07)
| Arithmetischer Mittelwert | Standardabweichung | |
|---|---|---|
| ByHand (v1.0) | 0,021 | 0,156 |
| JMapper Framework v1.6.1.CR2 vom 14.12.2016 | 0,026 | 0,162 |
| MapStruct v1.2.0.Final vom 17.10.2017 | 0,229 | 0,423 |
| Orika v1.5.2 vom 06.10.2017 | 0,548 | 0,530 |
| Selma v1.0 vom 01.05.2017 | 0,783 | 0,466 |
| reMap v4.1.1 vom 08.11.2018 | 3,069 | 0,591 |
| Dozer v5.5.1 vom 22.04.2014 Anmerkungen | 11,953 | 1,288 |
| ModelMapper v2.3.2 vom 26.11.2018 | 41,252 | 2,821 |
Unter den folgenden Rahmenbedingungen wurde dieser Test durchgeführt.
- Java Version 8 (64 Bit, OpenJDK)
- Linux Ubuntu 64 Bit 18.04.1 LTS
- Desktop-Rechner
- Speicher 12 GB
- Prozessor Intel Core i7 CPU 975 @ 3,33 GHz * 8
Aktualisierung der Messung: Neu: Betriebssystem, OpenJDK vom 05.12.2018 (v1.4.1, jdk8-06)
| Arithmetischer Mittelwert | Standardabweichung | |
|---|---|---|
| ByHand (v1.0) | 0,018 | 0,136 |
| JMapper Framework (v1.6.1.CR2) | 0,019 | 0,137 |
| MapStruct (v1.2.0.CR2) | 0,207 | 0,409 |
| Orika (v1.5.1) | 0,524 | 0,519 |
| Selma (v1.0) | 0,788 | 0,467 |
| reMap (v1.0.3) | 3,193 | 0,531 |
| ModelMapper (v1.1.0) | 7,055 | 1,031 |
| Dozer (v5.5.1) | 11,684 | 1,193 |
Unter den folgenden Rahmenbedingungen wurde dieser Test durchgeführt.
- Java Version 8 (64 Bit, OpenJDK)
- Linux Ubuntu 64 Bit 18.04.1 LTS
- Desktop-Rechner
- Speicher 12 GB
- Prozessor Intel Core i7 CPU 975 @ 3,33 GHz * 8
Update des Beitrags mit reMap vom 05.10.2017 (v1.4.0, jdk8-05)
| Arithmetischer Mittelwert | Standardabweichung | |
|---|---|---|
| ByHand (v1.0) | 0,018 | 0,134 |
| JMapper Framework (v1.6.1.CR2) | 0,019 | 0,138 |
| MapStruct (v1.2.0.CR2) | 0,181 | 0,390 |
| Orika (v1.5.1) | 0,515 | 0,538 |
| Selma (v1.0) | 0,786 | 0,470 |
| Neu: reMap (v1.0.3) | 2,940 | 0,649 |
| ModelMapper (v1.1.0) | 7,102 | 1,114 |
| Dozer (v5.5.1) | 11,518 | 2,255 |
Unter den folgenden Rahmenbedingungen wurde dieser Test durchgeführt.
- Java Version 8 (64 Bit, ORACLE)
- Linux Ubuntu 64 Bit 14.04.05 LTS
- Desktop-Rechner
- Speicher 12 GB
- Prozessor Intel Core i7 CPU 975 @ 3,33 GHz * 8
Update des Beitrags mit Selma vom 03.04.2017 (v1.3.0, jdk8-04)
| Arithmetischer Mittelwert | Standardabweichung | |
|---|---|---|
| ByHand (v1.0) | 0,017 | 0,134 |
| JMapper Framework (v1.6.1.CR2) | 0,016 | 0,129 |
| MapStruct (v1.2.0.Beta2) | 0,179 | 0,393 |
| Orika (v1.5.0) | 0,536 | 0,527 |
| Neu: Selma (v0.15) | 0,776 | 0,454 |
| ModelMapper (v0.7.8) | 6,930 | 1,113 |
| Dozer (v5.5.1) | 11,315 | 1,244 |
Unter den folgenden Rahmenbedingungen wurde dieser Test durchgeführt.
- Java Version 8 (64 Bit, ORACLE)
- Linux Ubuntu 64 Bit 14.04.05 LTS
- Desktop-Rechner
- Speicher 12 GB
- Prozessor Intel Core i7 CPU 975 @ 3,33 GHz * 8
Update des Beitrags mit JMapper Framework vom 27.05.2016 (v1.2.3, jdk8-03)
| Arithmetischer Mittelwert | Standardabweichung | |
|---|---|---|
| ByHand (v1.0) | 0,016 | 0,133 |
| Neu: JMapper Framework (v1.6.0.1) | 0,015 | 0,123 |
| MapStruct (v1.0.0.Final) | 0,173 | 0,388 |
| Orika (v1.4.6) | 0,531 | 0,557 |
| ModelMapper (v0.7.5) | 5,624 | 0,964 |
| Dozer (v5.5.1) | 11,138 | 1,325 |
Unter den folgenden Rahmenbedingungen wurde dieser Test durchgeführt.
- Java Version 8 (64 Bit, ORACLE)
- Linux Ubuntu 64 Bit 14.04.04 LTS
- Desktop-Rechner
- Speicher 12 GB
- Prozessor Intel Core i7 CPU 975 @ 3,33 GHz * 8
Update des Beitrags mit ModelMapper vom 28.03.2016 (v1.1.0, jdk8-02)
| Arithmetischer Mittelwert | Standardabweichung | |
|---|---|---|
| ByHand (v1.0) | 0,023 | 0,163 |
| MapStruct (v1.0.0.Final) | 0,161 | 0,368 |
| Orika (v1.4.6) | 0,534 | 0,526 |
| Neu: ModelMapper (v0.7.5) | 5,624 | 0,956 |
| Dozer (v5.5.1) | 11,220 | 1,137 |
Unter den folgenden Rahmenbedingungen wurde dieser Test durchgeführt.
- Java Version 8 (64 Bit, ORACLE)
- Linux Ubuntu 64 Bit 14.04.04 LTS
- Desktop-Rechner
- Speicher 12 GB
- Prozessor Intel Core i7 CPU 975 @ 3,33 GHz * 8
Erstellung des Beitrags am 19.07.2015 (v1.0.0, jdk8)
| Arithmetischer Mittelwert | Standardabweichung | |
|---|---|---|
| ByHand (v1.0) | 0,016 | 0,144 |
| MapStruct (v1.0.0.Beta4) | 0,152 | 0,372 |
| Orika (v1.4.5) | 0,514 | 0,534 |
| Dozer (v5.5.1) | 10,371 | 1,152 |
Unter den folgenden Rahmenbedingungen wurde dieser Test durchgeführt.
- Java Version 8 (64 Bit, ORACLE)
- Linux Ubuntu 64 Bit 14.04.01 LTS
- Desktop-Rechner
- Speicher 12 GB
- Prozessor Intel Core i7 CPU 975 @ 3,33 GHz * 8
Test am 02.08.2014 (Commit 739903, jdk7)
| Arithmetischer Mittelwert | Standardabweichung | |
|---|---|---|
| ByHand (v1.0) | 0,019 | 0,147 |
| MapStruct (v1.0.0.Beta2) | 0,285 | 0,458 |
| Orika (v1.4.5) | 0,529 | 0,547 |
| Dozer (v5.5.1) | 10,292 | 1,146 |
Unter den folgenden Rahmenbedingungen wurde dieser Test durchgeführt.
- Java Version 7 (64 Bit, OpenJDK)
- Linux Ubuntu 64 Bit 14.04 LTS
- Desktop-Rechner
- Speicher 12 GB
- Prozessor Intel Core i7 CPU 975 @ 3,33 GHz * 8
Test am 04.07.2014 (Commit FCC6F9, jdk6)
| Mittelwert | |
|---|---|
| ByHand (v1.0) | 0,071 |
| MapStruct (v1.0.0.Beta2) | 0,853 |
| Orika (v1.4.5) | 2,328 |
| Dozer (v5.5.1) | 46,259 |
Unter den folgenden Rahmenbedingungen wurde dieser Test durchgeführt.
- Java Version 6 (32 Bit, Oracle)
- Windows 7 Enterprise 64 Bit ServicePack 1
- VDI (virtueller Desktop)
- Speicher 4 GB
- Prozessor Intel Xeon CPU ES-2670 @ 2.60 GHz 2.59 GHz
Alle Tests, mit den unterschiedlichen Rahmenbedingungen, sind im GitHub-Verzeichnis zu finden.
Excel Arbeitsmappe: Das zweite Tabellenblatt enthält die Messwerte. Auf dem ersten Tabellenblatt sind die Messwerte des Einschwingvorgangs.
Die Maven-Befehle zur Durchführung der Tests befinden sind in diesem Kapitel Durchführen der Messungen beschrieben.
Die Umfragen
Umfrage vom 07.04.2017 bis zum 31.07.2017
Wer ist Ihr bevorzugter Java Bean Mapper?
- MapStruct (28%, 11 Stimmen)
- Dozer (21%, 8 Stimmen)
- ByHand (15%, 6 Stimmen)
- JMapper (15%, 6 Stimmen)
- ModelMapper (10%, 4 Stimmen)
- Orika (5%, 2 Stimmen)
- Spring Framework BeanUtils (3%, 1 Stimmen)
- Selma (3%, 1 Stimmen)
- Apache Commons BeanUtils (0%, 0 Stimmen)
Teilnehmerzahl: 39 (1 Stimmen)
Die Umfrage wurde am 31.07.2017 beendet. Diesmal gab es einen eindeutigen Sieger:
MapStruct mit 11 Stimmen vor Dozer mit 8 Stimmen. Herzlichen Glückwunsch!
Umfrage vom 19.07.2015 bis zum 19.10.2015
Wie schon geschrieben, verwende ich vor allem MapStruct. Wie ist das bei Euch?
Wer ist Ihr bevorzugter Java Bean Mapper?
- Dozer (33%, 3 Stimmen)
- Orika (33%, 3 Stimmen)
- MapStruct (33%, 3 Stimmen)
- Spring Framework BeanUtils (0%, 0 Stimmen)
- Apache Commons BeanUtils (0%, 0 Stimmen)
- ByHand (0%, 0 Stimmen)
Teilnehmerzahl: 9 (1 Stimmen)
Die Umfrage wurde am 19.10.2015 beendet. Diese Umfrage ging unentschieden zwischen Dozer, Orika und MapStruct mit jeweils 3 Stimmen aus.
Der Quellcode und Download
Quellcode ansehen bei GitHub:
Java Bean Mapper
Download einer ZIP-Datei von GitHub:
Java Bean Mapper
Die Maven Befehle
Eclipse Konfiguration neu erzeugen: $ mvn eclipse:clean eclipse:eclipse
Es wird das Eclipse Plug-in M2Eclipse verwendet.
Die Anwendungen bauen: $ mvn clean install
Durchführen der Messungen
Auf der Konsole in das Root-Verzeichnis des Projektes wechseln und die folgenden Befehle ausführen.
$ mvn clean install $ cd bean-mapper-test/ $ mvn -Dtest=PerformanceTestWithCompleteFixtures test $ mvn -Dtest=PerformanceTestWithIncompleteFixtures test

Benötigen Sie Unterstützung? Kontaktieren Sie ihn.
Hat Ihnen dieser Beitrag gefallen? Wir würden uns über Ihren Kommentar freuen! Bitte verwenden Sie Ihren bürgerlichen Namen.
- Wer ist der optimale Java Bean Mapper? - Freitag, 22. September 2023
- Spring Boot Webanwendung: Die ersten Schritte (Tutorial) - Montag, 28. März 2016
- Mainframe-Zugriff via Java - Sonntag, 04. Mai 2014
")
")
")
")
")
")

Oh, vielen Dank – jetzt weiß ich auch, wie ich meinen alten Mapper weiterbenutzen kann.
Es gab einige Anfragen, ob ich Java 17 berücksichtigen kann. Da gibt es leider ein paar Probleme. Nicht alle Mapper kompilieren unter JDK 17. Die folgenden beiden Exceptions treten dabei auf:
java.lang.reflect.InaccessibleObjectException : Unable to make field <field> accessible: module <xxx> does not "opens <yyy>" ...java.lang.reflect.InaccessibleObjectException : Unable to make <methode> accessible: module <xxx> does not "opens <yyy>" ...Das betraf die Mapper: Orika, JMapper Framework und
reMap.Natürlich kann ich diese Mapper aus dem Test herausnehmen. Was beim JMapper womöglich geschehen wird, da dieser Mapper nicht mehr weiterentwickelt wird. Andere Mapper haben eine Anpassung angekündigt (reMap).
EDIT: reMap hat den Fehler in der Version 4.3.0 gefixt!
Es können auch VM Optionen gesetzt werden:
--add-opens=<xxx>/<yyy>=ALL-UNNAMEDIch weiß nicht, ob das eine tragfähige Lösung ist. Was meint ihr?
Ende November kommt Spring Boot 3 mit Spring Framework 6, welches auf das JDK 17 aufsetzt. Da müssten die Mapper eigentlich nachziehen, damit die Nutzer umstellen können.
EDIT:
Ich hab schon mal den BranchDie Änderungen wurden in den Branch master zusammengeführt.java-17bereitgestellt, falls jemand mit JDK 17 spielen möchte.Viele Grüße
Frank
Orika
Fehler:
java.lang.reflect.InaccessibleObjectException: Unable to make protected native java.lang.Object java.lang.Object.clone() throws java.lang.CloneNotSupportedException accessible: module java.base does not "opens java.lang" to unnamed moduleJVM Optionen:
--add-opens=java.base/java.lang=ALL-UNNAMEDJMapper Framework
Fehler:
java.lang.reflect.InaccessibleObjectException: Unable to make protected final java.lang.Class java.lang.ClassLoader.defineClass(java.lang.String,byte[],int,int,java.security.ProtectionDomain) throws java.lang.ClassFormatError accessible: module java.base does not "opens java.lang" to unnamed modulejava.lang.reflect.InaccessibleObjectException: Unable to make field private final java.util.Comparator java.util.TreeMap.comparator accessible: module java.base does not "opens java.util" to unnamed modulejava.lang.reflect.InaccessibleObjectException: Unable to make field protected java.lang.reflect.InvocationHandler java.lang.reflect.Proxy.h accessible: module java.base does not "opens java.lang.reflect" to unnamed modulejava.lang.reflect.InaccessibleObjectException: Unable to make protected java.lang.String java.text.AttributedCharacterIterator$Attribute.getName() accessible: module java.base does not "opens java.text" to unnamed modulejava.lang.reflect.InaccessibleObjectException: Unable to make field private static final java.util.Map java.awt.font.TextAttribute.instanceMap accessible: module java.desktop does not "opens java.awt.font" to unnamed moduleAlle Fehler werden durch die Bibliothek XStream ausgelöst.
JVM Optionen:
--add-opens=java.base/java.lang=ALL-UNNAMED--add-opens=java.base/java.util=ALL-UNNAMED--add-opens=java.base/java.lang.reflect=ALL-UNNAMED--add-opens=java.base/java.text=ALL-UNNAMED--add-opens=java.desktop/java.awt.font=ALL-UNNAMEDreMap
Fehler:
java.lang.reflect.InaccessibleObjectException: Unable to make protected final java.lang.Class java.lang.ClassLoader.defineClass(java.lang.String,byte[],int,int,java.security.ProtectionDomain) throws java.lang.ClassFormatError accessible: module java.base does not "opens java.lang" to unnamed moduleDer Fehler werden durch das Tool CGLIB ausgelöst.
JVM Optionen:
--add-opens=java.base/java.lang=ALL-UNNAMEDEDIT: Dieser Fehler wurde in der Version 4.3.0 gefixt.
Der folgende Fehler trat mit der Umstellung auf Java 21 auf:
java.lang.UnsupportedOperationException: Cannot define class using reflection: Unable to make protected java.lang.Package java.lang.ClassLoader.getPackage(java.lang.String) accessible: module java.base does not "opens java.lang" to unnamed moduleJVM Optionen:
--add-opens=java.base/java.lang=ALL-UNNAMEDBeeindrückende artikel. Ich frage mich ob Smooks würde qualifizieren für mapper hier? Ich habe smooks benutzt eher für xml -> javabean, und da ist es ja auch gut. Smooks ist nicht aktiv weiterentwickelt, aber ist schon ein etablierten über 10 jahte alte library.
http://nikkijuk.blogspot.com/2013/08/simple-xml-to-jpa-data-service-with.html
Hallo,
vielen Dank für diesen ausführlichen Vergleich.
Ist euch vielleicht ein Framework bekannt, welches ähnlich dem EqualsBuilder von Apache Commons funktioniert, jedoch 2 Objekte unterschiedlicher Typen miteinander vergleichen kann? Quasi als Prüfung ob ein Mapper korrekt funktioniert hat und alle Felder berücksichtigt hat.
Nein, im Moment fällt mir da nichts ein. Ich hab immer JUnit-Test geschrieben, falls so eine Prüfung notwendig war.
Viele Grüße
Frank
Hallo, vielen Dank für diesen ausführlichen Artikel!
Eine weitere interessante Mapping Library ist ReMap (https://github.com/remondis-it/remap). Dieser Mapper unterstützt als einziger einen komfortablen Weg, ein Objekt-Mapping zu testen. Für Regressionstests ist dies ein wichtiges Feature. Des Weiteren vermeidet dieser Mapper, das Code angepasst werden muss (wie z.B. bei Lösungen mit Annotations).
Vielleicht wäre diese Bibliothek auch ein guter Kandidat für diesen Artikel 🙂
Spannender Vergleich der Mapper! Vielen Dank dafür.
Ich war an der Performance von unserem Mapper reMap interessiert und habe bei der Gelegenheit einen Pull Request erstellt, in dem reMap in das Test-Framework aufgenommen wurde (https://github.com/frank-rahn/performance/pull/1). Würde mich auch freuen, wenn der Mapper hier noch aufgenommen wird 🙂
Ein paar weitergehende Infos zu diesem Mapper gibt es auch im folgenden Blog-Artikel: https://reflectoring.io/autotmatic-refactoring-safe-java-mapping/
Viele Grüße,
Tom
Hallo Tom!
Ein Pull Request? Cool! 🙂 Da gebe ich mich mal dran …
Vielen Dank und Grüße,
Frank
Hallo Tom,
ich habe den Pull Request in das Test-Framework aufgenommen und den Mapper in die Seite integriert.
Vielen Dank für den Request und viele Grüße,
Frank
Danke dir!
Gruß,
Tom
Ich hab den Mapper aufgenommen.
Vielen Dank für die Anregung.
Viele Grüße,
Frank
Wie sieht es mit zwei weiteren typischen Problemen aus?
a) No Contructor: Beispiel XMLGregorianCalendar LocalDate
b) „Coded Enum“, i.e. enum ANREDE { HERR(„01“), FRAU(„02“), UNBEKANNT(„03); … } String
Wie gut können die Mapper-Frameworks damit umgehen? Wie aufwändig sind „Custom Converter“ zu integrieren?
Beispiele für Custom Converter sind in den folgenden Packages implementiert:
de.rahn.performance.beanmapper.vendorsde.rahn.performance.beanmapper.selmaFür den Mapper Selma die Converter
DateCustomMapperundCustomCalendar.de.rahn.performance.beanmapper.mapstructMapper JMapper
In der Klasse
JMapperTestBeansMapperBeanab Zeile 44.Bei den Mapper MapStruct kann anstatt das Mapper Interface auch eine abstrakte Klasse verwendet werden, die dann Methode zur Konvertierung implementiert.
Bei den modernen Mappern sind die Unterstützungen recht ausgereift.
Interessantes Thema.
Ich selbst, habe erst vor kurzem, Mappings von einer XML Datei, auf verschiedene Entitäten durchführen müssen.
Was ich dabei immer schwierig finde, ist quasi einen Adapter zu schreiben, der sowohl das Mappen, als auch die Validierung übernehmen kann. Gerade wenn man nicht auf einen DOM Parser setzen kann.
Dabei komme ich meistens nicht drum herum, eine Implementierung von Hand vor zu nehmen.
Eventuell müsste man sich mal für solche Fälle einen eigenen Generator schreiben.
Falls es für die XML ein XSD Schema gibt, kann ein JAXB Generator verwendet werden. Mittlerweile sind diese Konverter ganz gut. Für eine komplexe Validierung kann die Bean Validation JSR-303 oder die Validatoren von Spring verwendet werden. Hibernate (
org.hibernate:hibernate-validator:5.3.5.Final) hat da eine gute JSR-303 v1.1 Implementierung.Genau das wäre ein guter weg gewesen. Leider existiert kein XSD Schema bzw. liegt nicht weiter vor.
Des Weiteren ist die XML recht groß bzw. wusste ich nicht genau ob JAXB eine SAX oder DOM Implementierung nutzt, wobei hier die DOM Variante zu langsam gewesen wäre.
Jetzt benutze ich hier pro Entität einen Adapter, welcher quasi etwas unkonventionell die Methoden dieser nochmals abbildet bzw. im Grunde die setter Methoden. Die einzelnen XML Attribute, werden dann als String Objekte übergeben und von der jeweiligen Methode validiert und in den spezifischen Typ umgewandelt bzw. in den, welcher von der Entität erwartet wird.
Das ist leider etwas mehr Aufwand, wobei der Vorteil darin liegt überall direkt eingreifen zu können. Aber ja JAXB wäre in dem Fall einfacher gewesen.
Vielleicht ist ein Blick auf die Streaming API for XML (JSR-173) hilfreich oder interessant.
Die StAX-API bietet den Zugriff auf die XML-Daten über einen Cursor an
XMLStreamReader, der auf eine Stelle (Element) im Dokument zeigt und durch die Anwendung mit (next()) weiter bewegt wird. Alternativ kann auch mit einem Iterator-VerfahrenXMLEventReadergearbeitet werden. Durch den Pull-Ansatz sollte die Implementierung etwas lesbarer werden – ggf. kann dieses mit JAXB kombiniert werden.Ah Interessant. Ich werde mir StAX bzw. auch den „hibernate-validator“
mal anschauen. Leider stecke ich noch nicht so richtig in der JEE Welt drinne 😉 Aber Vielen Dank schon mal für die tolle Hilfe und den guten Artikel 🙂
Vielen Dank
Hi,
es wäre cool wenn du noch http://www.selma-java.org/ mit aufnehmen könntest.
LG
Peter
Bin dabei 🙂
Erledigt!
Vielen Dank für Ihre Zusammenstellung!
Welche Mapper würden Sie aktuell einer Firma guten Gewissens empfehlen im Hinblick auf die weitere Pflege? Mich irritiert beim Blick ins gitHub, dass sowohl bei Orika wie bei Dozer die meiste Entwicklung im Jahr 2013 stattfand und in letzter Zeit kaum noch Weiterentwicklungen / Bugfixes zu finden sind und keine neue Releases mehr herauskamen. Denken Sie, dass diese Mapper weiterhin gewartet werden oder ist zu befürchten, dass wenn man jetzt grösseren Entwicklungsaufwand in die Erstellung von mappings mit diesen Tools steckt, man in einer Sackgasse landen könnte („never ride a dead horse“)?
Ich würde aktuell entweder das JMapper Framework oder MapStruct verwenden.
Bei MapStruct wird es demnächst die Version 1.1.0 geben – diese ist im Moment im Beta-Test.
Der ModelMapper wird zur Zeit mäßig entwickelt. Bei den anderen Mappern sieht es düster aus. Wobei bei Dozer aber auch ein sehr hoher Reifegrad erreicht wurde. Der Dozer ist aber auch der häufigste genutzte und älteste Mapper.
It would be interesting to see how JMapper competes with the technologies you mentioned (i’m the founder).
https://github.com/jmapper-framework/jmapper-core
Ich hab den JMapper hinzugefügt. Er hat eine beeindruckende Performanz – er kann mit der Geschwindigkeit des Mappers ByHand mithalten.
thank you for adding JMapper between the java bean mappers.
However, you can switch destination and source positions without rewrite the configuration, obviously if the relationship is the same:
... @PostConstruct public void initialize() { JMapperAPI jMapperAPI = new JMapperAPI() .add(mappedClass(...) .add(conversion("dateToCalendar").from("date").to("date") .body("java.util.Calendar c = java.util.Calendar.getInstance(); c.setTime(${source}); return c;"))) .add(conversion("calendarToDate").from("date").to("date") .body("return ${source}.getTime();")) .add(mappedClass(...)); domainToXmlMapper = new JMapper(XmlTable.class, DomainTable.class, jMapperAPI); xmlToDomainMapper = new JMapper(DomainTable.class, XmlTable.class, jMapperAPI); } ...If you want to avoid creating multiple instances of JMapper you should use
RelationalJMapper.Ich habe die Klasse
JMapperTestBeansMapperBeanentsprechend angepasst.ModelMapper wäre auch noch eine erwähnenswerte Alternative…
Ich habe den ModelMapper hinzugefügt. Er liegt von der Performanz hinter Orika. Da er aktuell noch entwickelt wird, muss man sehen wie er sich entwickelt.
Sorry für die verspätete Umsetzung 🙁 Beim nächsten Mapper werde ich schneller sein – versprochen!
Die Werte in der Tabelle zu ModelMapper sind um den Faktor 10 zu hoch angegeben.
Es müssten 0.5624 ms sein, statt 5,624, wie angegeben
Die Werte in der Tabelle wurden aus dem Excel-Sheet (Zum Excel-Sheet bei Git-Hub), welches bei der Messung geschrieben wird, abgelesen.
Der Wert für den arithmetischen Mittelwert des ModelMappers befindet sich in der Zelle F7 in der Tabelle Performanz Messung.
Wie kommen Sie auf den Faktor 10?
1) Die Aussage „Dieser Mapper ähnelt den schon vorher beschriebenen Mappern Orika und Dozer und sortiert sich auch entsprechend mit der Performanz ein.“ bezüglich ModelMapper scheint den Messergebnissen nicht zu entsprechen ( 0,531 ms für Orika vs. 5,624 ms für ModelMapper)
2) Eigene Tests mit komplexen Objektstrukturen unterstützen die Performanz von ModelMapper, hier habe ich um die 0.5 ms gemessen.
3) Eine Messung mit Ihrer Testsuite habe ich selber nicht vorgenommen, Wenn diese tatsächlich einen Performance-Unterschied den Faktor 10 von Orika gegenüber ModelMapper zeigt, ist die Aussage in 1) zumindest irreführend.
Zu 3) und 1), ich werde diese Aussage ändern, so dass sie klarer wird.
Zu 2) würde mich interessieren welche Versionen (ModelMapper, JDK, etc.) sie verwenden.
Ich habe den Text nun überarbeitet. Ich habe zufällig gesehen, das sich die Version von ModelMapper und einige anderen Mappern erhöht haben. Ich werden die TestSuit aktualisieren.